
The variables in the NLSY97 main file are documented through a codebook, supplemental documentation, and error updates. This section outlines these three components of the NLSY97 documentation and discusses the key types of information found in each.
Codebook
The codebook is the principal element of the NLSY97 documentation system and contains information intended to be complete and self-explanatory for each variable in a data file. The NLS Investigator allows easy access to each variable's codebook information and permits the user to print a codebook extract for selected variables.
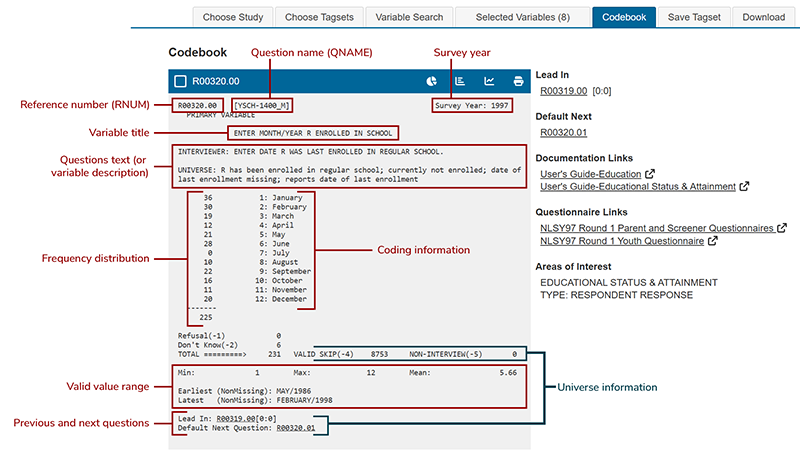
Each variable is presented as a codeblock (see Figure 1 and Figure 2). The top left of the codeblock displays the reference number (RNUM), followed by the question name (QNAME) and survey year. The variable title appears directly below, with the question text or variable description underneath. This section may include interviewer instructions and universe statements; for created variables, it contains archivist notes. The main body of the codeblock shows the frequency distribution, including coded response values and corresponding counts. Below the frequency table is universe information, indicating valid skips and non-interviews, followed by the valid value range. Links to the previous and next questions appear at the bottom, indicating the item’s position in the questionnaire. A right-hand panel provides documentation links and topical classifications. Many codeblocks also include special notes designed to assist in the accurate use of data.
Figure 1. NLSY97 questionnaire item codeblock
Click to view larger version of Figure 1. NLSY97 questionnaire item code block
{kind=link}
Figure 2. NLSY97 created variable codeblock
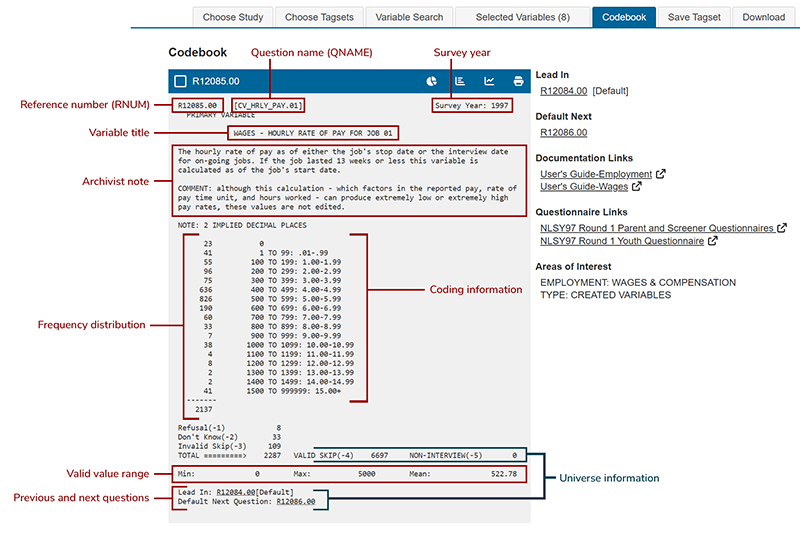
Click to view larger version of Figure 2. NLSY97 created variable code block
{kind=link}
Questionnaire item or question name (QNAME)
The question name provides the location of the question in the survey instrument or identifies it as a created variable. In the first example, the question name YSCH-1400 shows that the variable is based on a question in the schooling section of the youth instrument. In the second example, the question name CV_HRLY_PAY.01 indicates that the variable is created. For more information on how question names are assigned, refer to Survey Instruments.
Reference number (RNUM)
A reference number is a unique identifying number assigned to each variable in the data set. Generally, once assigned to the variables from an interview, reference numbers will never change unless there are special circumstances. Reference numbers may begin with R, S, T, U, Z, or E (E for Event History variables).
Coding information
Each codeblock entry presents the set of legitimate codes that a variable may assume along with a text entry describing the codes. Coding information for a given variable in the NLSY97 codeblock is not necessarily consistent with the codes found within the questionnaire. If the two sources are different, the codebook is current and the questionnaire information should not be used in analysis. For example, an additional code may be added during data processing if a significant number of respondents gave the same answer to the "other--specify" option in an answer list. The following types of code entries occur in NLSY97 codeblocks:
Dichotomous variables
Dichotomous (or variables answered yes/no), uniformly coded "Yes" = 1 and "No" = 0. Other dichotomous variables have frequently been reformulated to permit this convention to be followed.
Discrete variables
Discrete (categorical), as in the case of 'Month Enrolled in School.'
Continuous variables
Continuous (quantitative), as in the case of 'Hourly Rate of Pay' in Figure 2. These variables have continuous data but are presented in the codebook using a convenient frequency distribution. Note that rate of pay variables often have two implied decimal points.
Valid data are generally positive numbers. In a small number of variables, negative responses are possible; users should check the minimum values allowed for each question to clarify whether negative numbers are permissible. The following missing value conventions are used throughout the data:
- Noninterview -5
- Valid Skip -4
- Invalid Skip -3
- Don't Know -2
- Refusal -1
Frequency distribution
In the case of discrete (categorical) variables, frequency counts are normally shown in the first column to the left of the code categories. In the case of continuous (quantitative) variables, a distribution of the variable is presented using a convenient class interval. The format of these distributions varies.
Universe information
The universe information found in the codebook includes:
Universe totals
Two totals are presented: (1) The sum of the frequency counts for each coding category is located below the individual codes. (2) The sum of the valid responses plus missing response counts of "refusals," "don't knows," and "invalid skips" can be found in the TOTAL=======> field. The number of respondents who were not asked a question because it did not apply to them--that is, "valid skips (-4)"--is also depicted.
Universe skip patterns
The following detailed universe information will enable users to trace the flow of respondents both backward and forward through the CAPI questionnaire:
- "Go to # XXXXX," appended to certain coding categories, indicates that respondents selecting that answer category were routed to the next question specified.
- "Lead In(s) # XXXXX" identifies the question or questions immediately preceding the codeblock question through which the universe of respondents was routed. Each lead-in number is followed by the relevant response value indicators (e.g., (Default), (ALL), etc.)
- "Default Next Question" specifies the next question that all respondents to the current question will be asked unless some skip condition indicates otherwise.
Valid values range
Depicted below the frequency distribution is information relating to the range of valid values for that particular distribution. "MINIMUM" indicates the smallest recorded value exclusive of skips, refusals, and don't knows. "MAXIMUM" indicates the largest recorded value. The MAX of 5000 ($50.00) in the 'Hourly Rate of Pay' question means that it was the highest value recorded. The computer-assisted interview contains internal range checks that limit responses to those between predesignated values, warn interviewers to verify non-normative values, and bolster the information provided by the traditional minimum and maximum fields.
Hardmax and Hardmin fields
Hardmax and Hardmin fields denote the highest and lowest values that were accepted during the interview. Dates (e.g., month/day/year of the respondent's birth (%birth3%) and current interview (%curdate4%)) are often used as Hardmin and Hardmax values in order to restrict responses to certain questions to values within that range, as in the 'Enter Month/Year R Last Enrolled in School' example. Responses outside this range must be entered by the interviewer in the comment field; valid numbers are included in the data.
Softmax and Softmin fields
Softmax and Softmin fields cover ranges where an answer may exceed normal limits yet remain within absolute limits; such answers are accepted after verification. A Softmax set to $200,000 on an income question will trigger an alert to interviewers that a higher value is unusual.
Topcoded values
Confidentiality issues restrict release of all income and asset values. To insure respondent confidentiality, the top 2 percent of reported values for many income variables are all converted to one set value. This "topcoded" value is calculated separately for each variable by averaging all the values which exceed the limit for that variable.
Question text
When an NLSY97 variable is taken directly from the questionnaire, the verbatim of the question or the instructions to interviewers appear beneath the variable title. If a single question is the source for more than one variable, the first variable contains the question text, while subsequent variables prompt the user to refer to the variable containing the text.
Archivist information, notes, etc.
Some variables include additional information for users regarding inconsistencies in the data, methods of variable derivation, references to supplemental documentation, and so on. These notes generally appear beneath the variable title or question verbatim.
Codebook supplements
Variable creation procedures and supplemental coding information are provided within the Codebook Supplement, an HTML document included with the data set. This information is not available in the NLSY97 codebook pages. The attachments and appendices in the following list can be found in the NLSY97 Codebook Supplement.
NLSY97 Codebook Supplement attachment and appendices:
Attachment 1. Census Industrial and Occupational Classification Codes. This document lists the 3-digit 1990 Census codes and the 4-digit 2002 Census codes used to classify job and training information (Census Bureau, 1990 Census of Population Alphabetical Index of Industries and Occupations, Washington, DC: U.S. Government Printing Office, 1991; www.census.gov.)
Appendix 1. Education Variable Creation. This document provides the programs for several created variables related to education. These include, among others, enrollment status, type of school, date received diploma, highest grade completed, and number of schools attended.
Appendix 2. Employment Variable Creation. This appendix provides programs for created employment variables, including hourly rate of pay, hourly monetary compensation, number of weeks worked, total tenure at job, and number of jobs held.
Appendix 3. Family Background Variable Creation. This appendix of created variable programs contains those dealing with family background, such as household size, marital status, fertility and child status, marriage and cohabitation history, and citizenship status.
Appendix 4. Geographic Variable Creation. Several variables in the main data set provide information about the respondent's area of residence, permitting researchers to identify key characteristics of the area without needing access to the restricted-use Geocode data. Included in this appendix is a summary of the four Census geographic regions, an explanation of the MSA/central city status variable, and the definition for the rural vs. urban variable.
Appendix 5. Income and Assets Variable Creation. This document provides the creation procedures for income and assets created variables. These include household net worth and gross household income, as well as receipt of public assistance.
Appendix 6. Event History Creation and Documentation. This appendix explains the structure of the event history variables and describes the creation process.
Appendix 7. Continuous Month Scheme and Crosswalk. This document explains the structure of the event history month-by-month and week-by-week status arrays and provides crosswalks from continuous month/week numbers to actual month and year dates.
Appendix 8. Instrument Rosters. A number of rosters are used to organize information during various parts of the interview. This appendix identifies these rosters and shows how they were used in different parts of the survey. It also lists the variable names, titles, and reference numbers for the various instrument rosters used in each interview.
Appendix 9. Family Process and Adolescent Outcome Measures.. This document summarizes the creation procedures for the various scales and indexes created by Child Trends, Inc. The appendix also presents the results of Child Trends' statistical analyses of the scales, indexes, and a number of related attitude and behavior variables.
Appendix 10. AT-ASVAB Scores. This appendix discusses the administration of the Armed Services Vocational Aptitude Battery (ASVAB) to NLSY97 respondents. Topics include an explanation of the computer-adaptive test, the scoring of the ASVAB, and the variables available in the NLSY97 data set.
Appendix 11. Collection of the Transcript Data (High School). This appendix describes the survey materials used to collect data in the two waves of the NLSY97 Transcript Survey and explains the procedures and criteria for data entry and coding. It also lists specific details about individual Transcript Survey variables.
Appendix 12. Post-Secondary Transcript Study. This appendix describes the NLSY97 post-secondary transcript data collection that culled information on students' enrollment patterns, courses they took, and their performance in those courses.
Appendix 13. Cross-Cohort NLSY79/97 Overview. This appendix provides information on a NLSY79/NLSY97 cross-cohort beta release available on Investigator. The dataset harmonizes NLS data across two cohorts, giving users opportunities to perform cross-cohort comparisons.
Appendix 14. NLSY97 COVID-19 Supplement. This appendix explains a supplemental COVID-19 survey, fielded in the spring of 2021 to document the effects of the pandemic on respondents’ jobs and health. Respondents received invitations to complete a short (about 12 minute) web questionnaire about their experiences during the pandemic.
NLSY97 Geocode Codebook Supplement attachments:
Geocode Codebook Supplements: Contain supplemental coding information specific to the restricted-use Geocode data.
Attachment 100. 1990 Census Bureau State and County Codes. This attachment provides coding information for the state and county variables on the NLSY97 restricted-use Geocode data. These variables use the current Federal Information Processing Standards (FIPS) codes.
Attachment 101. MSA Codes. This document lists the Metropolitan Statistical Area (MSA) coding scheme used for NLSY97 geocode variables. It also presents Consolidated Metropolitan Statistical Area (CMSA) codes, New England Consolidated Metropolitan Area (NECMA) codes, and Primary Metropolitan Statistical Area (PMSA) codes.
Attachment 102. IPEDS Data and College Identification Codes. This attachment explains the Integrated Postsecondary Education Data System (IPEDS), and how this and other codes are used to identify the colleges reported by NLSY97 respondents.
Attachment 103. Migration Distance Variables for Respondent Locations. To support research on respondent mobility, survey staff created a series of variables for the distance between respondent addresses at each interview round as described in this attachment.
Attachment 104. Codebook Pages for Geocode and Zipcode Variables. This attachment presents codebook pages for the restricted-use NLSY97 geocode, zipcode, and census tract variables. These codebook pages show the answer categories, frequency distributions, and other related information for the variables available in the restricted-use Geocode data and at the BLS national office (zipcode and census tract variables). These pages are provided to help users determine whether the geocode information would be appropriate for their research needs in terms of content, sample size, etc.
Restricted-use data
Information about access to restricted-use geographic and school survey data is available on the Accessing Data page.
Additional documentation
Documentation for the NLSY97 includes the following items:
Technical Sampling Report: Youth Survey
This technical manual published by NORC describes the procedures used to select the youth sample. The manual includes weights and standard errors for the initial survey year.
Interviewer Reference Manuals/Materials
Field interviewers have ready access to general and specific instructions that guide them in the administration of the electronic questionnaire. Interviewers can click on "help screens" that are linked via HTML to the appropriate questions throughout the instrument. The Interviewer Reference Manual reproduces these help screens so that researchers can view the various definitions and other pieces of information used during the interview.
Error updates
When data errors are discovered within the data file, the correction is made and the date file is updated. These updated files then become the default files on NLS Investigator. NLSY97 Errata notices can be found in the Other Documentation section.