
The codebook provides information on item nonresponse, that is, which questions respondents declined to answer, answered as "don't know," or were skipped through. Also available in the database are timing variables that provide information on how long it took respondents to complete the total interview and to complete individual sections. In 2019, a separate timings dataset was added that includes a more extensive set of timings for select variables and survey years.
Item nonresponse
Missing data, or nonresponse, occurs for a number of reasons in the NLSY97 survey. First, a number of respondents may not participate at all that survey year, causing all information for those respondents in that particular survey year to be missing. (Note: data that are missing because of a non-interview situation are coded with a -5). The created variable "Reason for Noninterview" (RNI) is available in each survey round and provides counts for the different reasons (unable to be located, refusal, deceased, etc.) a respondent is not interviewed. The extent of non-participation in each survey round is illustrated in Retention & Reasons for Non-Interview.
A second reason missing data occurs is that respondents do not provide a valid answer to a question. When this happens, interviewers make a determination about whether to mark the answer as a 'refusal' or a 'don't know' value. Interviewers are trained to distinguish between refusal and don't know responses. For example, a refusal usually stems from such respondent comments as "That's none of your business," "I don't want to say," "I'm not comfortable telling you that," or "I don't want to answer." A 'don't know' response is coded from respondents comments such as, "I have no idea," "I don't know how I could guess," "I wouldn't know," or "I'm not sure how to answer that." Standard interviewing protocol calls for interviewers to try to convert an item non-response either by allaying the concerns underlying a refusal (for example, by assuring privacy or citing the research reasons for a particular questionnaire item) or by providing cognitive aids to the respondent who "doesn't know" (for example, asking "Do you remember what season it was?" or "Do you have a guess what the range might be?). Only if conversion attempts are ineffective do interviewers record a 'refusal' or 'don't know' response.
A valid skip is another reason for missing data. Respondents do not answer every question of the survey. For instance, some questions might apply to only females or a certain age range. Users should trace back skip patterns to determine whether a respondent was skipped out because a given topic was inapplicable to him/her or because the respondent answered similar questions along a different path. Survey questions not on a path answered by the respondent are coded with a -4.
Missing data can also occur when there is an incorrect flow in the survey instrument. Incorrect flows may result in some respondents being skipped over a set of questions that should be answered while others answer questions that they should not have been asked. NLS data archivists have removed from the data most of the extraneous question responses. While extra information can be removed, missing data is not imputed in the NLSY97 surveys. Missing data caused by this reason is flagged with a special 'invalid skip' code. The use of CAPI for surveys reduces the number of invalid skips in complex questionnaires; nevertheless, some invalid skips are still possible in CAPI data. When these errors are found, the CAPI survey can be corrected in the field to prevent further invalid skips, but the missing data from already completed cases are not retrieved.
Missing data values
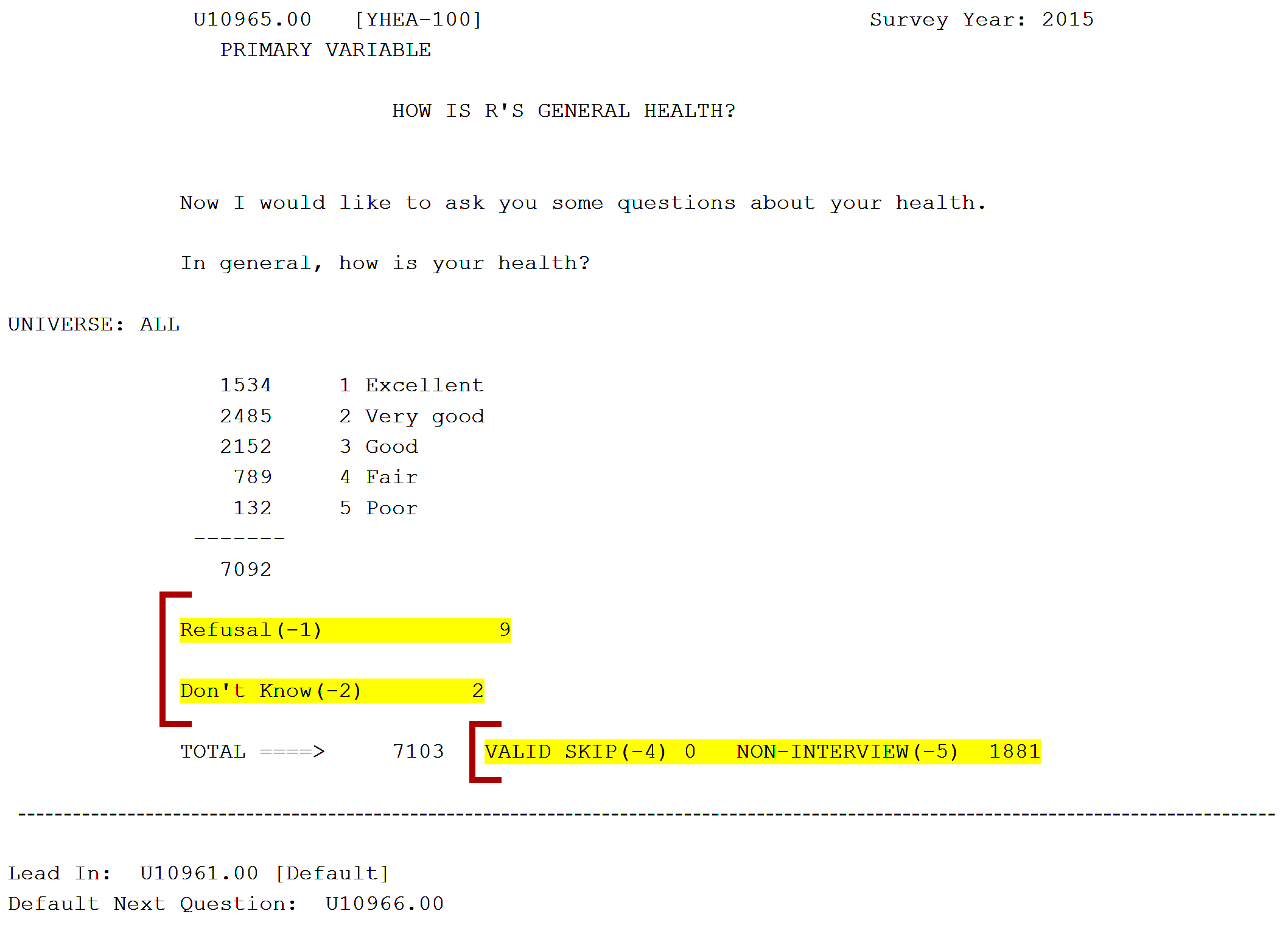
All missing data are clearly flagged in the NLSY97 data set with five negative values: (-1) refusal, (-2) don't know, (-3) invalid skip, (-4) valid skip, and (-5) noninterview. In general, these five negative values are reserved as missing value flags. As an example, Figure 1 shows the item, "How is R's general health?" Within the item codeblock, the user can see that 7,092 respondents in 2015 gave responses ranging from "excellent" to "poor," nine people refused to answer (-1), two people reportedly did not know (-2), and 1,881 people were not interviewed that survey year (-5). In this example, there were no valid skips (-4) or invalid skips (-3).
Figure 1. NLSY97 Questionnaire Item Codeblock with Nonresponse Highlighted
As would be expected, survey questions that are more sensitive in nature tend to yield a higher amount of missing data in the "refused" categories.
To improve accuracy of reporting, many of the more sensitive questions are found in the self-administered questionnaire (SAQ) portion of the survey, which in-person respondents answer privately using a laptop. Note: If the survey is done by phone, the SAQ section is not self administered and must be administered verbally by the interviewer.
Rounds 9 and up also include the following response variables (prefix Rx_ changes according to round number, e.g. R9_, R10_):
- Rx_RESPONSES. The total number of responses provided by the respondent during the round 9 interview.
- Rx_PCT_DK. The percentage of all the respondent's responses to round 9 interview questions that were "Don't Know (-2)."
- Rx_PCT_REF. The percentage of all the respondent's responses to round 9 interview questions that were "Refused (-1)."
Interview timings
In rounds 5 and up, timing variables are available that provide the total time taken to conduct the interview (in seconds) and section timings for each section of the survey. For example, Household - Rx_TIM_HHI, Schooling - Rx_TIM_SCH, Employment - Rx_TIM_EMP, Health - Rx_TIM_HEA, etc. (prefix Rx_ changes according to round number, e.g. R5_, R6_). Starting in round 8, timings for subsections, such as migration, household roster, schooling attainment, also became available.
Rx_TIM_INTVW. The total time taken for the interview is the total interview time taken in seconds, excluding the time taken for the locator section and interviewer remarks. Note: Round 7 timings are available only in the restricted use geocode data file.
Important information: Timing data
Timing data can be found by selecting "Timing" in the Area of Interest drop-down menu when executing a variable search in the NLS Investigator.
NLSY97 timings dataset
In 2019, the NLS program created timings data based on select variables and years of the NLSY97. The timings are mainly for questions related to sexual activity, pregnancy, smoking, drug use, delinquent behaviors, criminal activity, and expectations. These 1,093 timing variables are now included in a separate dataset available to the public in the NLS Investigator. The dataset can be located by first choosing "NLSY97" in the cohort drop-down selection list and then choosing "Select Timings" within the NLSY97 drop-down list.
All timings in this dataset are reported in milliseconds. To convert to seconds, divide by 1000.
What are timings?
Timing variables are automatically generated during a respondent's interview and measure the time of the interaction on a particular question. Measurement starts as soon as the question screen appears on the interviewer's computer and stops when the survey program moves to the next question. Therefore, the data include the time for the interviewer to read the question and for the respondent to provide an answer. An invalid skip (value = -3) has been assigned when the timing for a question is over an hour and no other timing information is available, the timings data for the case are missing, or in rare instances when the timings data have been corrupted (e.g., a negative timing). In certain circumstances, a respondent will have multiple instances of a question time. This would happen in cases in which the respondent answered the question and then returned to that question to change/clarify/check their answer. It may also occur in instances in which the respondent answered the question and then returned to another prior question to change/clarify/check their answer, and then the question reappeared on the screen as the interviewer moved forward through the interview to get back to the next question.
Reference numbers and question names
Reference numbers (RNUMs) for the timing variables start with the letter J (for example, J0000200). The question names (QNAMEs) for the timing variables incorporate the names of the underlying survey questions, with the following pattern:
[QNAME in survey]_[Round question asked]
For example, YSAQ-299_R01 indicates that this timing is for YSAQ-299 asked during round 1. Additional instances of the variable timing are indicated with _T2 for the second instance or _T3 for the third instance. In this case, YSAQ-299_R01_T2 is the second time that the interview screen for that question was opened in round 1 and YSAQ-299_R01_T3 indicates the third time. Up to three instances are included in the data.